Руководство пользователя
Оглавление
- Введение
- Политика безопасности
- Как сообщить о проблеме
- Доступ к ресурсам
- Создание SSH-ключей
- Ваши пароли и SSH-ключи
- Доступные файловые системы
- Установленное ПО
- Настройка программного окружения
- Запуск задач
- Использование контейнеров
- Список очередей и политика их использования
- Ограничения ресурсов в очередях
- Упоминание в публикациях
- Иногда задаваемые вопросы
- Как узнать, на каких узлах выполнялась программа
- Каким образом распределяются физические машины для каждой задачи
- Как получить образ памяти (core dump) для программ, скомпилированных с помощью Intel Fortran
- У меня не работает самая простая MPI-программа на Fortran. Спасите!
- Статические массивы размером более 2GB в Intel Fortran
- Как заставить работать FTP в Midnight Commander
- Sbatch выдает сообщение «No partition specified or system default partition»
- При компиляции программ на языке Fortran компилятором Intel выдается предупреждение о функции feupdateenv
- Я поместил в .bash_profile «module load …», но при заходе на машину выдается сообщение об ошибке
- Программа на языке Fortran завершается, говоря «MPI_ERR_TYPE: invalid datatype»
- Работа с кириллическим текстом
- Странные падения программ на Fortran
- Хочется использовать больше памяти, чем есть на ядро
- Задача сразу завершается не оставляя сообщений об ошибках
- В моём каталоге появились странные файлы core.*
- Задача не начинает расчёт, а висит со статусом PD, AssocGrpCpuLimit
Введение
Данный документ предназначен пользователям вычислительных кластеров HPC2 и HPC4.
Приводим определение некоторых терминов, связанных с данными кластерами.
- ОВК
Кластеры HPC2 и HPC4 находятся в ведении Объединённого вычислительного кластера (ОВК) – подразделения НИЦ «Курчатовский институт» в Москве. - ЦКП
На ресурсах ОВК функционирует Федеральный центр коллективного пользования научным оборудованием «Комплекс моделирования и обработки данных исследовательских установок мега-класса» (ЦКП).
Кластеры HPC2 и HPC4 входят в ЦКП (это важно при упоминании наших вычислительных ресурсов в ваших публикациях). - HPC4
Термин «кластер HPC4» требует дополнительного разъяснения.
В данном документе мы используем этот термин для указания совокупности вычислительных ресурсов, изначально составлявших кластер HPC4, и ресурсов кластера HPC5, введённых в эксплуатацию позднее.
При объединении указанных выше вычислительных ресурсов были использованы следующие общие элементы:- параллельная файловая система,
- система управления ресурсами (Slurm),
- средства доступа к ресурсам.
- Login-узел
Будем называть login-узлом головную машину кластера, на которую вы заходите для взаимодействия с данным кластером.
Login-узел используется, в частности, для сборки программ, постановки их в очередь к исполнению на вычислительных узлах, для передачи на кластер исходных данных для ваших расчётов и для передачи результатов выполнения ваших задач с кластера на ваши машины.
Кластер может иметь несколько login-узлов (в частности, на HPC4 используются два login-узла – для работы с вычислительными узлами, на которых установлены операционные системы разных версий).
Политика безопасности
При регистрации пользователя (см. раздел Регистрация пользователей, Шаг 3) требуется согласие с нашей политикой безопасности, поэтому вам нужно внимательно прочитать этот документ и следовать его предписаниям.
Как сообщить о проблеме
При возникновении любых проблем, относящихся к вашей работе на каком-либо из наших кластеров,
пожалуйста, напишите письмо в нашу службу сопровождения пользователей
по адресу «help![[AT]](/i/dog.png) computing
computing kiaeru».
kiaeru».
Нам будет удобнее работать с вашим обращением, если при составлении письма вы учтёте следующие рекомендации:
- тема письма должна содержать ваше имя пользователя (user name) и краткую формулировку сути проблемы;
- тело письма должно содержать достаточно подробное описание проблемы, в частности:
- при проблемах с доступом на какой-либо из кластеров следует указать название login-узла, который вы использовали для входа на кластер (например, ui4.computing.kiae.ru);
- при проблемах с выполнением задачи полезно указать следующее:
- идентификатор задачи (JOBID);
- название очереди, в которой она запускалась (например, hpc4-3d);
- способ запуска вашей задачи (например, вы запускали команду «sbatch test.sh» в каталоге /s/ls4/users/vasya/tests).
Доступ к ресурсам
Для доступа к вычислительным ресурсам наших кластеров используются следующие login-узлы:
- кластер HPC2, login-узел: ui2.computing.kiae.ru;
- кластер HPC4, login-узлы: ui4.computing.kiae.ru и ui4-el7.computing.kiae.ru.
Заход на указанные выше login-узлы кластеров осуществляется с использованием протокола SSH. Для соединения можно использовать программы SSH-клиентов, поддерживающие протокол SSH версии 2. Подойдут, например,
- Putty (Windows),
- OpenSSH (UN*X, входит в комплект практически всех современных UN*X-подобных операционных систем).
Для копирования файлов можно использовать следующие утилиты:
- scp (UN*X, входит в состав OpenSSH);
- WinSCP (Windows, графический интерфейс, две панели: локальная и удалённая машины),
- pscp.exe/psftp.exe (Windows, текстовой интерфейс).
Создание SSH-ключей
Для аутентификации на нашем кластере в настоящий момент используются SSH-ключи. Если вы не знаете, что это такое, то сейчас вам это будет, по мере возможности, объяснено.
Если коротко, то SSH-ключи – это пара файлов, один из которых называется закрытым ключом, обычно защищён паролем и не показывается никому, во избежание разных неприятностей. Второй файл называется открытым ключом и может быть показан кому угодно; более того, его нужно поместить на сервер, чтобы он начал вас пускать. Из открытого ключа, в-принципе, можно восстановить закрытый, но из-за сложности разложения чисел на простые множители на современных машинах это займет достаточно большое количество времени.
Так вот, вся штука заключается в том, что имея только открытый ключ сервер может проверить, есть ли у вас соответствующий ему закрытый ключ. А поскольку предполагается, что закрытый ключ есть только у вас (именно поэтому его так важно никому не показывать), то сервер сможет утверждать, что если проверка прошла успешно, то к нему стучитесь именно вы.
Теперь один из важных практических вопросов: как создать эти самые SSH-ключи (на сервер их положат наши администраторы, поэтому здесь вы можете быть спокойны).
Создание SSH-ключей на Unix-системах
Предполагается, что у вас установлен пакет OpenSSH, и, стало быть, есть утилита ssh-keygen. Запускаем:
$ ssh-keygen -t rsa -b 2048 Generating public/private rsa key pair. Enter file in which to save the key (/home/vasya/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your public key has been saved in /home/vasya/.ssh/id_rsa.pub. The key fingerprint is: 22:f7:7b:96:c5:4b:b2:0d:2d:9f:5f:67:57:48:46:37 vasyaСоответственно, если вы хотите сохранить ваш ключ не в /home/vasya/.ssh/id_rsa, а куда-то еще, вы можете ввести полный путь в ответ на приглашение «Enter file in which to save the key». Но если вы пока не очень в курсе, как использовать различные SSH-ключи для различных машин, то лучше оставить все как есть.
После отработки ssh-keygen закрытый ключ будет находиться в файле /home/vasya/.ssh/id_rsa, а открытый – в /home/vasya/.ssh/id_rsa.pub. Именно последний файл вам и нужно отослать нам. Пожалуйста, не перепутайте ;))
Если вы используете нестандартное имя файла с закрытым ключом, то вам либо придётся указывать его расположение каждый раз с помощью ключа «-i», либо добавить в файл ~/.ssh/config следующие строчки:
Host ui2.computing.kiae.ru
IdentityFile ~/.ssh/id_rsa-hpc2
Если вы используете один и тот же открытый ключ для нескольких наших
кластеров, то можно использовать настройки, в которых имя узла будет
содержать символ «*», который соответствует любому количеству
любых символов:
Host ui*.computing.kiae.ru
IdentityFile ~/.ssh/id_rsa-kiae
Создание SSH-ключей на Windows-системах
Putty
Для создания SSH-ключа вам нужно скачать программу PuTTYgen с
сайта
Putty.
Запускаем программу и выбираем тип ключа «SSH-2 RSA»,
а его размер – 2048 бит:
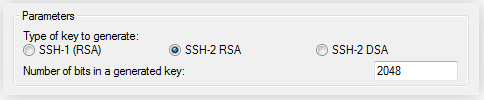
Нажимаем на кнопку «Generate».
Далее PuTTYgen создает ключ и предлагает ввести для него пароль:
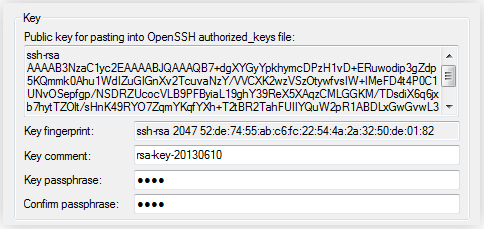
Пароль нужно выбирать такой, чтобы враг его не раскрыл, а вы –
не забыли.
Также можно ввести комментарий (любой).
Сохраняем private key (закрытый ключ) в файл mykey.ppk, а public key (открытый ключ) – в файл id_rsa.pub.
id_rsa.pub нужно послать нам, а на закрытый ключ нужно натравить Putty,
чтоб он знал, откуда его брать.
Картинка, я надеюсь, все объясняет:
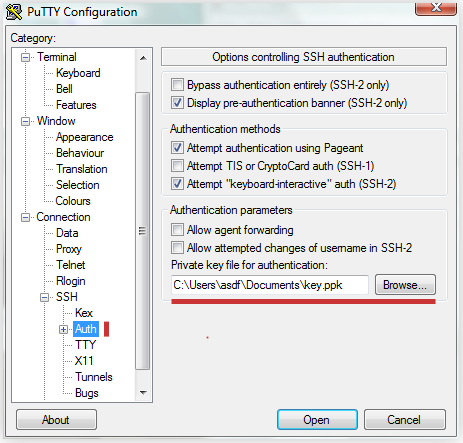
That's all, folks!
Tectia SSH Client (ssh.com)
Tectia SSH Client – это преемник Windows SSH Client от ssh.com. По нашему мнению, Putty лучше, но некоторые любят этот клиент, поэтому мы вас научим создавать ключи для SSH и в нем.
В меню «Edit» выбираем пункт «Tectia Connections…»,
в узле дерева слева «User Authentication» выбираем
«Keys and Certificates» и получаем примерно следующее окно:
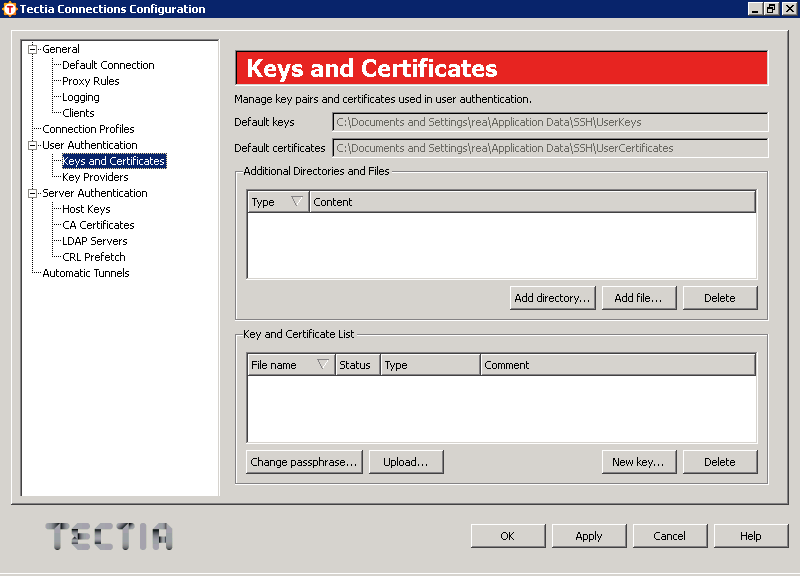
Нажимаем на кнопку «New key…» и получаем следующее окно,
в котором необходимо ввести параметры создаваемого ключа:
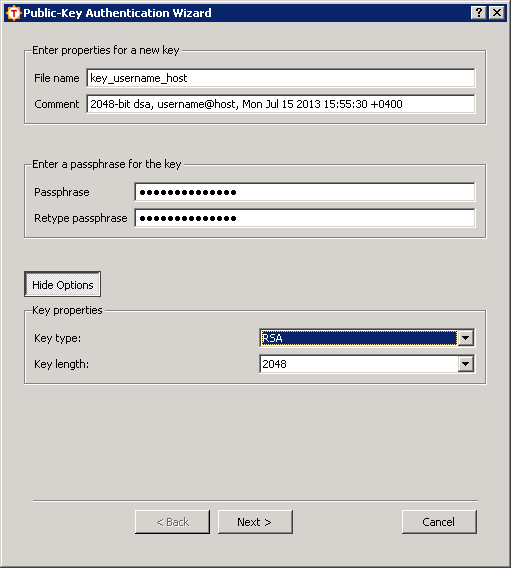
Ваши действия будут следующими:
- «File name», естественно, отвечает за имя файла с открытым и закрытым ключами, которые будут сгенерированы. Имя нужно ввести.
- В поле «Comment» можно ввести комментарий, например, для чего предназначен этот ключ.
- В поля «Passphrase» и «Retype passphrase» необходимо ввести пароль для закрытого ключа.
- Далее необходимо нажать кнопку «Advanced Options», выбрать тип ключа «RSA», а количество бит – не менее 2048.
Нажав кнопку «Next» вы инициируете создание ключевой пары,
что может занять некоторое время.
Далее вы увидите следующее окно, предлагающее нам загрузить ключ
на сервер:
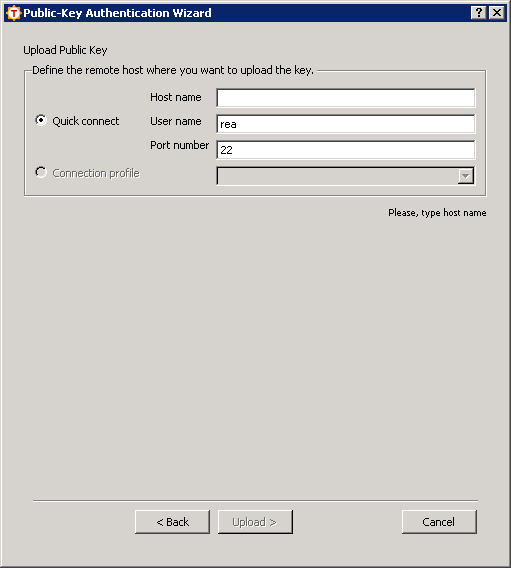
Нажимаем «Cancel», ничего никуда загружать не нужно.
После этого мы видим первоначальное окно,
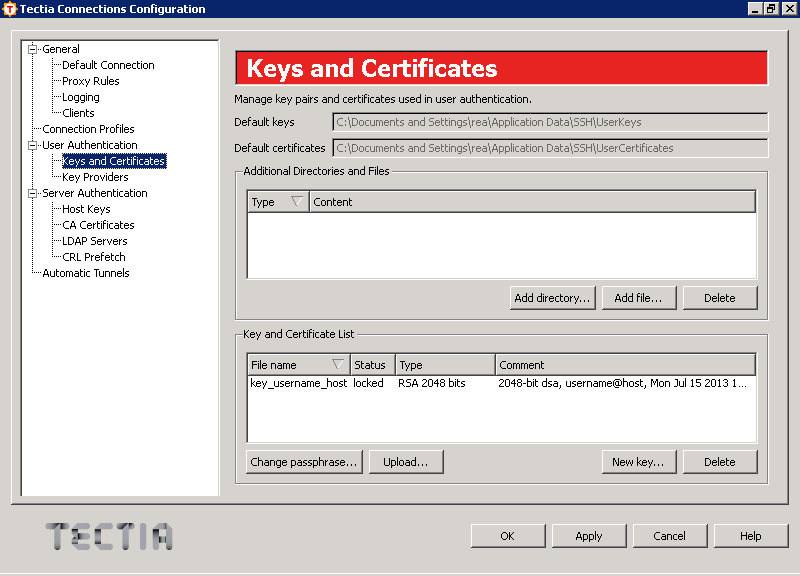
но уже с одним (или, если у вас до этого были созданы публичные ключи,
с еще одним) ключом.
Поле «Default keys» сверху окна показывает, где сохраняются
ваши открытый и закрытый ключ.
Файл с закрытым ключом не имеет расширения, файл с открытым ключом имеет
расширение «.pub»:
That's all, folks!
Экспорт ключей из Putty/Tectia в формат OpenSSH
Если вам нужно экспортировать закрытый ключ с Windows-системы в Unix и вы использовали Putty или Tectia SSH Client, то сейчас мы объясним, как это можно сделать. Для преобразования необходим Putty key generator, в одном из предыдущих разделов объясняется, где его взять.
Шаг номер 1: вы загружаете существующий закрытый ключ в Putty key generator
(меню «File», пункт «Load private key»).
Получается примерно такое окно:
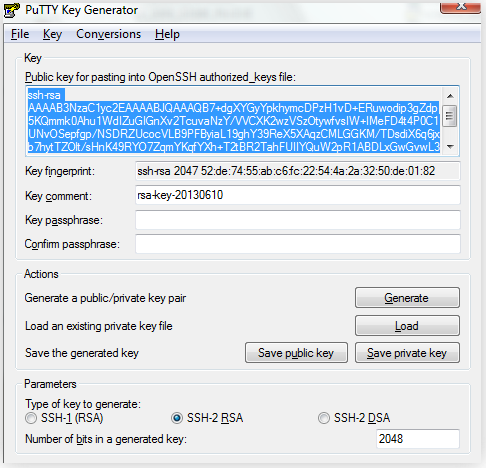
Шаг номер 2: находим в меню «Conversions» пункт «Export OpenSSH key», вводим имя файла и выбираем каталог, в который будет сохранен закрытый ключ. Пароль сохраненного закрытого ключа будет таким же, как и пароль к исходному ключу в формате Putty.
Шаг номер 3: переносим закрытый ключ на Unix-машину, лучше – копированием файлов с использованием какого-то offline-носителя, а не через сеть или электронную почту.
Экспорт ключей из OpenSSH в формат Putty/Tectia
Если вам нужно экспортировать закрытый ключ с Unix-системы использющей OpenSSH в Windows, где вы используете Putty или Tectia SSH Client, то этот раздел – для вас.
Шаг номер 1: находим в меню PuTTY Key Generator «Conversions» пункт
«Import key», выбираем файл с ключом в формате OpenSSH,
вводим в открывшемся окне пароль для этого закрытого ключа и получаем
примерно такое окно:
Шаг номер 2: нажимаем в этом окне кнопку «Save private key»,
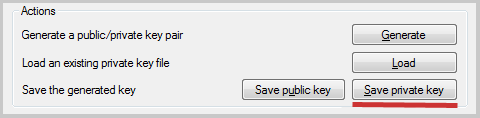
выбираем имя файла и каталог, куда будет сохранен файл закрытого ключа.
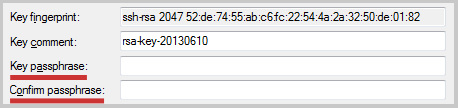
Пароль для этого файла будет совпадать с паролем исходного ключа.
Если вы хотите его изменить, то перед сохранением ключа в формат Putty
необходимо ввести новый пароль в поля «Key passphrase»
и «Confirm passphrase»:
Типичные проблемы, возникающие при работе с SSH-ключами
При переносе SSH-ключей между различными операционными системами иногда возникает путаница. Ниже будет показано, как отличить файлы с ключами различных форматов.
Вот как должен выглядеть закрытый ключ для Unix-систем:
-----BEGIN RSA PRIVATE KEY----- Proc-Type: 4,ENCRYPTED DEK-Info: DES-EDE3-CBC,F45627B370E24DB1 XD4u/JN7snja3Wl1Dj7eoIGKiAx8IOALvLbmUTik4liCMxk3OPW1eOTQxAV7CJom PMfH5kOMAber45D4yiQzGYGc/mxStfNjtm8V7j6N4acb6E4BKRUGmv7ZkLrw9csr PpZzSQ5wTYiXRzJE55r5Q+CWd2V5qVJypAW2Q8pUMGF6A+DSxno1LSc8TwQ43o8G FTGw8bCEgnfhXmGGLm6lirbXOQIJRCqbszBlPGZ4uNNaLAkbs7O85dqjKFsTMXLv XCloDn+8wFr8eg7mZAkAjs0jz9l0PBDAYxivzrw97GRmemHynqsDSaE4F6pxaed9 lhxLwtK0VZH1ofEZUdT64lHJUX4oow9t2r7ajrItlnGBo7redY4yTaLKArxSOdVG AKOO0PyAv4J2Mm0F8bNwYecUskpu+efr4n2343jJKmXONc+KxfZjdDBFsVFkmpv3 p4AyryKisiT/BbgAdLYXomVKeMSBQe6eDUSQtIabirOBsk63aiJAy5j5yzqzudJ8 IzmCuNB7p4SkmqiPoqW7vPR5G2PlK4G790vszcYr221w5QE3keVB/iRszyJrQHl8 k9LzX3oejumGknLubihJqelWBDP54tGlL88YB9uPQ4jSUFOv8+M68ebBONVh1eB9 uUe0C3FwxUHm53i7v8DnDFki8onnk6mUxa8pgIJJBUMdDnie0CGh1QAT6NiLE2tT mnBIG7pHxU3HbnUdA+yDbvvfvkoP6Lc5XWCQsn8SNjDv2gPkNrYRbxaRjgOykTiQ ZHEEU+JYwzyOtw6tbuOOUfcH4BqKhVc0YwZrDDKHOXAo0PgGcuxoE8EAKZptV3lz XyFZjtfw5KvulRmwjuMydu0Alg5qo8cpyCSFCyxRQlWjyiPwOI3w7ixLpZFpQGMQ bmVrgLKB/XdgPnmXj7K/6KD2YU2FxZjCFdbGdDUY6E/cBAHD/7sHjGV6CXJ72ZkO oGWhLgkRk/Dy9doysm6DwCiLS7K/cddUkZcFKvxzBdmOaTt+jlB2tXKDvRAJIwrm GiEx2LlKjbbgoTrV+rjuFFgVhsHualxP52NsvujQZVpeFtomZ/amk3ceOMTFTkab QJcb/zOWjG+PrtiQ6BR/Te0kl44S2L3AR5AOCVD13k1nEOZ1yHyCtti04xM7JavP Jy+RSUmIt7hSD9A0e4nHHXEhPZnGgG8ekVrR6FEQ+0FbvYLpv05Ir+igQSMftZwA YdBjA16KeJL4jKAOWzVe5tdA0BQcJvPjzPK97N6HkCrbcmSy7mQAsXCZ7BcInwwa UD8zOeH8Ii8atzy+YM+bQRoRfQLkzpJ3pVe68ZwqKFHl+YQNlh0sCJ3slihLKKVR mUXutpa2c385Yb9djLifKaSdPYG3rutmdx7HY1JzYvvkIau+ixiO1H6dETI8tLZC 4l1FTSisGt4LZyH3WgPpQzhiWs0KX9yIQ/0lqRhgEL8zqqDm3jo/jIQdFMVfHBlI YSKjoySUN3GXk8MfBsxxgbJRNwfcdiuB5qcsAxYkNVJgczHScEoM5NoatlHVlbyV Ymu8j7BqNZ5a1W/YYadEV2prdQeAUOTX8yGVq14MU/5X6uTZyCj9fQ== -----END RSA PRIVATE KEY-----Детали могут отличаться, но первая и последняя строчки почти всегда имеют вид
-----BEGIN RSA PRIVATE KEY----- -----END RSA PRIVATE KEY-----либо
-----BEGIN DSA PRIVATE KEY----- -----END DSA PRIVATE KEY-----Если вы пытаетесь использовать для Putty ключ в формате OpenSSH, то вам необходимо его сконвертировать. Без преобразования формата файла Putty не будет правильно распознавать ваш закрытый ключ.
Вот как выглядит закрытый ключ для Putty:
PuTTY-User-Key-File-2: ssh-rsa Encryption: aes256-cbc Comment: rsa-key-20130610 Public-Lines: 6 AAAAB3NzaC1yc2EAAAABJQAAAQB7+dgXYGyYpkhymcDPzH1vD+ERuwodip3gZdp5 KQmmk0Ahu1WdIZuGIGnXv2TcuvaNzY/VVCXK2wzVSzOtywfvsIW+IMeFD4t4P0C1 UNvOSepfgp/NSDRZUcocVLB9PFByiaL19ghY39ReX5XAqzCMLGGKM/TDsdiX6q6j xb7hytTZOlt/sHnK49RYO7ZqmYKqfYXh+T2tBR2TahFUIIYQuW2pR1ABDLxGwGvw L3T2laIT5Lt3//6ioCT0jlIkBuVii1hlm2quiyqogDs1U1ihOGL0wKNvhpds4Hfd wyRCjU1WJkZGGrLkdtvlg4AQhM7J8FVrYhTNZe90GJZXjnJP Private-Lines: 14 Xp4pdSAaE8Ftj9Va68OgwyTtO1V75m7cLmSHJSxzVaQCpw8zzn2gPeFnl/7fuusN Q1cZ8uDdpzI5E2+iEtM5hSn4SoOfH5eyhSa+FYObxj2IN+ylwS4vIbPmj7pY4Mom BGvxPdgZzKSITblxiE6YSFCNq4CmTIjtg/OXU5/slw7oifdEPcvPDudaGtztmv4a zSMPO9tvgrk1C5hzY5FfDoKpZHK94mgyjypHt7NEAbEls7GQCn7qTsng2Au2xeu/ l5ZDmb52zu/iLYb2JALnz+h5qyE2XFHsVjwyY+rzxstEWgkgCZdCrbOexHrgIlyc sKr7H3c3pJ7ZsVsXFvoWLVRcFhq/8Sa7rTr7ONkaUBPUiF00fdp2UiC3bI5U9FlQ MRhXKEfogEdJDZdWvGibHyX2on8PkJzDZCuQaG/K6pm92VHhv8AYMs4ADfrUVg6k Y7A5q+sDtXM1QAiL/Qct1Hr8uAp8sLfKYsnBSc1teTHdIjugEjfOn8zMR96vgFEi bXWcA8o4WROMJ42f9Dy3hTsg7kf4ZcGmY8ua3deYABu3KuAttUNTshAF5qfPGjEk gR53PoPgLzA1IeYIgX9w9INHQgfolsWguuTb5i1UdXKnk7SwXxmyl1o9F3DSRGu9 pl7bKLQGjrDcaLyxavUyZoHb1zwiDoGBJ4pefC1e1LKJ6OUiWXCWcUsTIeuj9q+L eEr4RWr59A/11jGvbrTi2Qjxp71aqHmQjsiXonT/bl6Xydb3zS8e4AmJJifxu179 EgfXBPePYarjX6PPivt6uURnRDyTVU6jXJl4ddIudtpUpY14M4BekA4MZ9m2PMsx S5syWlWFvfPIoHMLpdDWV/D2kimvamcEbbCxK0uI9VlVHNmTotI49OYt0XaHrZGS Private-MAC: 464d517a6c7b61184a4f7f1ec2ad4f33c1b15294Характерными особенностями данного формата является первая строка вида
PuTTY-User-Key-File-2: ssh-rsaвслед за которой довольно часто следуют строки вида
Encryption: aes256-cbc Comment: rsa-key-20130610Если вы пытаетесь использовать на Unix-системах ключ в формате Putty, то вам необходимо его сконвертировать. Без преобразования формата файла OpenSSH не будет правильно распознавать ваш закрытый ключ.
Ваши пароли и SSH-ключи
Ваши пароли и закрытые части SSH-ключей не нужно показывать или передавать никому. Вообще никому, даже если вас об этом просит служба поддержки или администратор, с которым вы переписываетесь или разговариваете по телефону. Любой, кто спрашивает вас о вашем пароле – это человек, который пытается методами социальной инженерии вытащить из вас секретные сведения и пробраться на наш кластер. Исключений – нет, пожалуйста, запомните это.
Также не нужно давать ваш пароль и/или SSH-ключ вашим коллегам, близким, и, вообще, кому бы то ни было. Если кто-то хочет получить доступ на наш кластер, то он должен заполнить заявку (см. раздел Регистрация пользователей, Шаг 4), и мы ее обязательно рассмотрим.
При необходимости замены или добавления SSH-ключа следует обратиться
в нашу службу поддержки – написать письмо по адресу
«helpcomputingkiaeru» и приложить открытую часть нового ключа.
Не следует пытаться самостоятельно изменить открытый ключ на login-узле.
При обнаружении нарушений указанных выше правил обращения с SSH-ключами мы вынуждены будем заблокировать ваш доступ на наши login-узлы до момента выяснения всех обстоятельств, и, возможно, даже навсегда.
Установленное ПО
По поводу того, как настраивается окружение для разработки, написано в разделе настройка рабочего окружения.
Компиляторы
- Intel C/C++ Compiler 14.0.2: компилятор запускается командой icc. Для компиляции MPI-приложений нужно использовать команду mpicc.
- Intel Fortran Compiler 14.0.2: компилятор запускается командой ifort. Для компиляции MPI-приложений нужно использовать команды mpif77 и mpif90.
Библиотеки MPI
- Platform MPI 9: может быть использован как с программами, скомпилированными с помощью Intel C/C++ и Intel Fortran, так и с программами, скомпилированными с помощью GNU C/C++.
Доступные файловые системы
При проведении расчётов используется файловая система Lustre.
На кластере HPC2 для размещения домашних каталогов пользователей и групповых каталогов используется файловая система NFS.
Параллельная файловая система Lustre
У каждого из наших суперкомпьютеров есть своя, доступная только ему,
параллельная файловая система, основанная на Lustre.
Она доступна как с login-узла этого суперкомпьютера, так и с узлов его
вычислительного поля, и должна использоваться для хранения временных
данных расчётов и программного обеспечения.
В файлах сценариев запуска задач необходимо использовать пути к каталогам в файловой системе Lustre (для кластера HPC2 путь должен начинаться с /s/ls2, для HPC4 – с /s/ls4).
Мы не используем квоты на Lustre (чтобы не препятствовать исполнению
задач, промежуточные файлы которых занимают большое пространство).
Поэтому, пожалуйста, будьте разумны в плане занимаемого на Lustre
места, и удаляйте, либо переносите на другие хранилища все файлы,
которые более не требуются для проведения ваших будущих расчётов.
Ниже описаны особенности работы с файловыми системами для каждого кластера.
Кластер HPC2
Домашняя файловая система на NFS
При входе на кластер HPC2 вы попадаете в свой домашний каталог /home/users/$USER. Домашние каталоги пользователей на данном кластере располагаются не в параллельной файловой системе, а в файловой системе NFS.
Эти каталоги доступны только с login-узла, вычислительное поле их не видит. Кроме пользовательских каталогов доступны, также, и групповые каталоги. Они именуются как /home/groups/gABCD, и доступны для чтения и записи всем членам указанной группы.
На NFS установлены групповые квоты для полного пространства,
которое занимают как индивидуальные пользовательские каталоги, так и
групповой каталог.
Квоты ставятся в соответствии с вашими заявками при регистрации группы,
при необходимости они могут быть несколько расширены.
По вопросам расширения нужно обращаться в нашу службу поддержки
(«helpcomputingkiaeru»).
Использование NFS для размещения домашних каталогов пользователей и групп позволяет уменьшить нагрузку на относительно медленную и ограниченную по ёмкости параллельную файловую систему кластера HPC2. Технически NFS располагается на нескольких независимых серверах и домашний каталог каждого из пользователей находится на конкретном сервере. Это означает, что при проблемах с одним NFS-сервером пострадают все пользователи с домашними каталогами, расположенными на нём, но другие пользователи будут иметь возможность продолжать работу.
Доступ к файловой системе Lustre
Для кластера HPC2 путь к файловой системе Lustre начинается с /s/ls2/.
Организация каталогов на Lustre на кластере HPC2 сходна с организацией каталогов в домашней файловой системе на NFS, доступны следующие каталоги:
- есть каталоги для каждого пользователя, они доступны по имени /s/ls2/users/$USER,
- существуют групповые каталоги, доступные как /s/ls2/groups/gABCD
Для хранения более постоянных объектов (например, программного обеспечения, каких-то вспомогательных данных, которые часто используются для многих вычислительных задач, и т.п.) предусмотрены каталоги со следующими именами:
- каталоги для каждого пользователя называются /s/ls2/u-sw/$USER,
- каталоги для группы называются /s/ls2/g-sw/gABCD.
Обмен данными между NFS и Lustre
Для запуска программы на счёт нужно разместить саму программу и исходные данные для расчёта в параллельной файловой системе Lustre. Там же окажутся файлы с результатами ваших расчётов. Предполагается, что вы будете копировать ваши данные между NFS и Lustre вручную (командами cp, rsync и другими).
В принципе, вы можете работать непосредственно на Lustre, но, поскольку она используется для хранения данных, к которым обращается значительная часть вычислительного поля, вы можете испытывать проблемы со скоростью работы с файлами: у вас будет долго работать команда ls, файлы в редакторе также будут долго открываться и сохраняться. Поэтому вам, скорее всего, будет значительно удобнее использовать Lustre и домашнюю файловую систему на NFS по их назначению.
Кластер HPC4
Для кластера HPC4 путь к файловой системе Lustre начинается с /s/ls4/.
При входе на кластер HPC4 вы попадаете в свой домашний каталог. Домашние каталоги пользователей /home/users/$USER на данном кластере являются символическими ссылками на каталоги /s/ls4/users/$USER в параллельной файловой системе Lustre.
Файловая система Lustre кластера HPC4 более производительная и имеет больший объём по сравнению с системой Lustre кластера HPC2, поэтому использование NFS для размещения домашних каталогов пользователей и групп не требуется.
Кроме пользовательских каталогов на кластере HPC4 при необходимости могут быть созданы групповые каталоги: /s/ls4/groups/gABCD.
Резервное копирование данных
Мы не обеспечиваем резервное копирование пользовательских данных.
Пожалуйста, периодически копируйте нужные вам данные (исходные данные, тексты программ
и сценариев запуска, и пр.) на свои рабочие машины или на какие-либо внешние хранилища.
Настройка программного окружения
В связи с тем, что на кластере могут использоваться различные комбинации установленного программного обеспечения, у нас используется несложная система настройки программного окружения для каждого пользователя. Называется она modules.
Например, чтобы воспользоваться компиляторами от Intel, выполните команду:
module load intel-compilersЧтобы скомпилировать параллельную задачу с использованием библиотеки MPI, выполните:
module load mpiВсё это можно сделать одной командой:
module load intel-compilers mpi
Следующая команда позволяет узнать, какие пакеты имеются в системе:
module availСледующая команда выдает список уже используемых в данном сеансе модулей:
module list
Более подробную информацию о системе «modules» можно узнать, запустив команду man module.
Для настройки пользовательского окружения на login-узле вполне достаточно поместить в файл ~/.bash_profile следующую строку:
module load mpi intel-compilersЭта строка говорит о том, что пользователь будет использовать библиотеки MPI (mpi) и компиляторы Intel C/C++ и Intel Fortran (intel-compilers). Естественно, не обязательно использовать именно эти конкретные инструменты, указанная строка является лишь примером.
В сценариях запуска для задач нужно указывать те же строки, что и в ~/.bash_profile. В разделе про запуск задач будут приведены соответствующие примеры.
На кластере HPC4 библиотека MPI входит в состав модулей «intel-compilers» и «intel-parallel-studio».
Запуск задач
Запуск задач осуществляется командой sbatch. Совсем подробную документацию можно посмотреть командой man sbatch, здесь будет рассмотрена только базовая функциональность.
Запуск простого сценария
Важно: batch-система умеет запускать только сценарии, поэтому не пытайтесь вместо сценариев запустить исполняемый файл: чаще всего из этого ничего не выйдет.
Самый простой пример: пусть мы хотим запустить на выполнение сценарий test.sh, находящийся в текущем каталоге и содержащий следующие строчки:
#!/bin/sh #SBATCH -D /s/ls2/users/eygene #SBATCH -o %j.out #SBATCH -e %j.err #SBATCH -t 01:00:00 #SBATCH -p hpc2-16g-3d hostname df date sleep 10 dateЭтот сценарий должен быть сделан исполняемым:
chmod +x test.sh
Запускаем сценарий на выполнение командой sbatch test.sh;
$ sbatch test.sh sbatch: Submitted batch job 19В ответ нам выдали идентификатор нашей задачи в очереди – 19.
Пользуясь этим идентификатором мы можем, например, узнать текущий статус нашей задачи:
$ squeue -j 19
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
19 hpc2-16g-3d test.sh eygene PD 0:00 2 (JobHeld)
В данном случае задача пока не была запущена. Вот как выглядит состояние
запущенной задачи:
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
19 hpc2-16g-3d test.sh eygene R 0:01 2 n[29-30]
Значение различных полей таблицы должны быть достаточно понятны.
Командой scancel можно удалить задачу из очереди: scancel 19.
После успешного завершения нашей задачи в каталоге /s/ls2/users/eygene, из которого задача запускалась образуются файлы 19.out и 19.err. В них было записано содержимое потоков стандартного вывода и стандартной ошибки вашей программы. Файлы будут находиться в каталоге /s/ls2/users/eygene, поскольку в сценарии мы написали
#SBATCH -D /s/ls2/users/eygeneчто заставляет Slurm при запуске задания переходить в указанный каталог. Этот каталог должен существовать и находиться на параллельной файловой системе Lustre, поскольку задание выполняется на рабочих узлах, которые из файловых систем видят только параллельную (см. раздел «Доступные файловые системы»). Если указанный в сценарии каталог отсутствует в файловой системе, задача завершается без сообщений об ошибках и без создания файлов *.out и *.err.
Файлы будут называться 19.out и 19.err, поскольку мы указали следующее:
#SBATCH -o %j.out #SBATCH -e %j.errВ этих директивах «%j» заменяется на идентификатор задачи, все остальное – оставляется как есть.
Директива
#SBATCH -t 01:00:00указывает на максимальное время выполнения данной задачи (в данном случае – один час). Если вы можете более-менее точно оценить верхнюю границу этого времени, пожалуйста, указывайте ее: это позволит планировщику более разумно планировать задачи. Однако вы должны понимать, что если ваша задача будет «убита», если время ее выполнения превысит указанное. Поэтому максимальное время выполнения лучше указывать с небольшим запасом.
Директива
#SBATCH -p hpc2-16g-3dуказывает, что мы хотим запустить задачу в очередь «hpc2-16g-3d». Чтобы понять, какую очередь нужно использовать для ваших нужд, пожалуйста, обратитесь к разделу «Список очередей и политика их использования»
Кстати говоря, вышеприведенные строчки вполне эквивалентны передаче утилите sbatch параметров командной строки «-o . -e .». И это работает для любых параметров sbatch, не только для указанных.
Запуск одиночной задачи
Запускать сценарии – это очень здорово, но чаще приходится запускать уже откомпилированные программы, подавать им на вход какие-то файлы и забирать результаты, которые сохраняются в другие файлы.
Но всё это несложно: передать программе любые аргументы можно из сценария, поэтому остаётся только вопрос копирования файлов на машину (с машины), где задача будет выполняться. Но это не проблема: на нашем кластере используется разделяемая файловая система, поэтому все узлы кластера видят одно файловое пространство. Поэтому вы спокойно можете запускать вашу задачу из любого каталога на login-узле – нижеприведенный сценарий запуска позаботится о том, чтобы задача «увидела» все те же файлы, которые есть в этом каталоге.
Вот какой файл сценария нужно использовать:
#!/bin/sh #SBATCH -D /s/ls2/users/eygene/my-precious-task #SBATCH -o %j.out #SBATCH -e %j.err #SBATCH -t 01:00:00 #SBATCH -p hpc2-16g-3d module load intel-compilers `pwd`/program mytask.in | tee mytask.log."$SLURM_JOBID"Здесь предполагается, что запускаемая программа называется “program” и она принимает на вход один аргумент – имя входного файла; в нашем случае “mytask.in”.
Конструкция “| tee mytask.log."$SLURM_JOBID"” применяется для того, чтобы весь вывод программы перенаправлялся в файл с именем “mytask.log.идентификатор_задачи”. Для программ, которые выдают результаты своей работы на экран это удобно, поскольку можно контролировать работу программы просматривая содержимое указанного файла. Если ваша программа ничего не выводит на экран, то эту конструкцию можно опустить, оставив только “`pwd`/program mytask.in”.
Запуск параллельной задачи
Предполагается, что вы ознакомились с разделом запуск одиночной задачи. Материал этого раздела лишь дополняет рассказанное там.
Как рассказывалось в разделе настройка программного окружения, в сценарии запуска задачи окружение должно настраиваться точно так же, как и в файле ~/.bash_profile. Будем предполагать, что вы используете следующие директивы команды module load: mpi и intel-compilers. Поэтому первым отличием сценария запуска MPI-задачи является наличие строк
module load mpi intel-compilersСтрого говоря, по-сравнению со сценарием для одиночной задачи тут появляется только загрузка модуля «mpi».
Следующим отличием является добавление еще одной строчки вида «#SBATCH …»:
#SBATCH -n 100Эта директива говорит о том, что вам нужно 100 ядер.
Последней модификацией в сценарии является добавление слова “$MPIRUN” в начало команды запуска задачи.
Собирая всё вместе, мы получаем следующий сценарий запуска задачи:
#!/bin/sh #SBATCH -D /s/ls2/users/eygene/my-precious-task #SBATCH -n 100 #SBATCH -o %j.out #SBATCH -e %j.err #SBATCH -t 01:00:00 #SBATCH -p hpc2-16g-3d module load mpi intel-compilers $MPIRUN `pwd`/program mytask.in | tee mytask.log."$SLURM_JOBID"
Использование контейнеров
Внимание!
Мы предоставляем пользователям возможность использования контейнеров
только на кластере HPC4 и только в очередях с CentOS 7
(*-el7-* и hpc5-v100-3d).
Использование технологии
контейнеризации
предоставляет пользователям новые возможности.
Контейнер создаёт для задач пользователя требуемую среду (образ ОС, необходимое пользователю ПО определённых версий).
Это, в частности, позволяет избавиться от установки пользовательского ПО непосредственно на кластер.
В результате упрощается добавление нового ПО, обеспечивается переносимость вычислений,
появляется возможность фиксировать версии ПО для воспроизводимости результатов.
На кластере HPC4 используется контейнерная платформа Apptainer версии 1.2 (см. руководство пользователя: Apptainer User Guide).
Образы контейнеров Apptainer сохраняются в виде файлов в формате *.sif. Для запуска ПО необходимо сохранить образ контейнера в системе хранения кластера.
Создание контейнеров
Существует несколько вариантов создания файла образа контейнера.
-
Загрузить готовый образ из репозитория Docker: $ apptainer build alpine.sif docker://alpine.
-
Собрать образ контейнера на login-узле ui4-el7.computing.kiae.ru на основе файла со сценарием сборки. В таком файле указывается базовый образ контейнера, набор команд по установке и настройке ПО, а также команды запуска ПО по умолчанию.
Пример файла:
Bootstrap: docker From: ubuntu:20.04 %post apt-get -y update apt-get -y install cowsay lolcat %environment export LC_ALL=C export PATH=/usr/games:$PATH %runscript date | cowsay | lolcatКоманда для сборки контейнера:
$ apptainer build lolcow.sif lolcow.def
Здесь Bootstrap – тип базового образа контейнера. Для локального файла – Bootstrap: localimage.
Поле From – имя базового образа.
Секция %post – набор команд для установки ПО в образ контейнера.
Секция %environment – определение переменных окружения.
Секция %runscript – команда для запуска ПО внутри контейнера.
-
Собрать контейнер в формате *.sif на другом сервере или персональном компьютере и скопировать его на кластер.
Запуск контейнеров
Команда для запуска ПО в контейнере имеет следующий вид:
apptainer exec {опции-контейнера} {путь-к-контейнеру.sif} {исполняемый-файл} {опции-командной-строки}
Пример команды запуска:
$ apptainer exec lolcow.sif cowsay moo
_____
< moo >
-----
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
Аргументы после имени файла образа будут распознаны как путь к исполняемому файлу и его опции командной строки. Если их не указывать, будет запущен исполняемый файл с опциями по умолчанию, которые указаны в образе контейнера.
Также доступна команда run, она позволяет передать опции командной строки, но использует исполняемый файл по умолчанию:
apptainer run {опции-контейнера} {путь-к-контейнеру.sif} {опции-командной-строки}
Команда shell позволяет начать интерактивную сессию внутри контейнера:
apptainer shell {опции-контейнера} {путь-к-контейнеру.sif}
Опции контейнера определяют параметры взаимодействия с операционной системой кластера. Здесь настраиваются связи между каталогами и переменные окружения.
Внутри контейнера для ПО представлена временная операционная система, к ней присоединяются (монтируются) каталоги системы хранения кластера, таким образом ПО в контейнере может может осуществлять чтение и запись данных, находящихся в системе хранения кластера. Изменения файлов за пределами присоединённых каталогов будут потеряны при остановке контейнера.
По умолчанию к контейнерам Apptainer подключается следующие каталоги: домашний каталог пользователя, каталог для временных файлов и набор служебных каталогов операционной системы. Для подключения дополнительных каталогов существует опция --bind, -B в формате --bind {каталог-на-кластере:каталог-в-контейнере}.
Пример использования:
$ ls /data bar foo $ apptainer exec --bind /data:/mnt my_container.sif ls /mnt bar foo
По умолчанию в контейнере определены все переменные окружения, определенные для пользователя в операционной системе кластера, плюс переменные окружения, указанные в файле контейнера. Переменные окружения из операционной системы кластера можно не передавать, указав опцию --cleanenv.
Можно указать дополнительные переменные окружения с помощью опции --env ИМЯ=Значение.
Пример использования:
$ apptainer run --env MSG=Hello\ HPC alpine.sif sh -c 'echo $MSG' Hello HPC
Запуск ПО с использованием MPI
Apptainer совместим с библиотеками MPI для многопроцессорных вычислений. Из-за особенностей MPI, для запуска необходимо использовать команду mpirun, установленную в операционной системе кластера.
Пример запуска:
$ mpirun -n 8 apptainer run hybrid-mpich.sif /opt/mpitest
При этом внутри контейнера должны быть доступны библиотеки MPI, совместимые с mpirun, используемым для запуска.
Рассмотрим два способа достижения этой цели.
-
Первый способ предполагает создание образа контейнера, включающего совместимые версии библиотек MPI. На кластере доступен базовый образ OpenMPI 4.1.0, который можно использовать для сборки новых контейнеров с его поддержкой: /s/ls4/sw/apptainer/openmpi-4.1.0.sif Его можно использовать вместе с соответствующим модулем openmpi/4.1.0.
Пример файла сборки образа:
Bootstrap: localimage From: /s/ls4/sw/apptainer/openmpi-4.1.0.sif %files mpitest.c /opt %post export OMPI_DIR=/opt/ompi export OMPI_DIR=/opt/ompi export PATH=$OMPI_DIR/bin:$PATH export LD_LIBRARY_PATH=$OMPI_DIR/lib:$LD_LIBRARY_PATH export MANPATH=$OMPI_DIR/share/man:$MANPATH echo "Compiling the MPI application..." cd /opt && mpicc -o mpitest mpitest.c %runscript /opt/mpitestСборка образа:
$ apptainer build mpitest.sif mpitest.def
Запуск:
$ srun -p hpc5-el7-3d -n 4 --pty bash $ module load openmpi/4.1.0 $ mpirun apptainer run mpitest.sif Hello, I am rank 0/4 Hello, I am rank 1/4 Hello, I am rank 2/4 Hello, I am rank 3/4
-
Второй способ предполагает подключение библиотек MPI из операционной системы кластера, в этом случае не нужно включать их в образ контейнера. Необходимо знать местоположение библиотек MPI и подключить их к контейнеру так, чтобы приложение смогло их найти при запуске. Кроме того, приложение в контейнере должно быть совместимо с версией MPI библиотек на кластере.
Пример файла сборки образа:
Bootstrap: docker From: ubuntu:22.04 %files mpitest /opt %environment export PATH="$OMPI_DIR/bin:$PATH" export LD_LIBRARY_PATH="$OMPI_DIR/lib:$LD_LIBRARY_PATH" %runscript /opt/mpitestСборка образа:
$ apptainer build mpitest-bind.sif mpitest-bind.def
Запуск:
$ srun -p hpc5-el7-3d -n 4 --pty bash $ module load openmpi/4.1.0 $ export OMPI_DIR=/s/ls4/sw/openmpi/4.1.0 $ export IB_DIR=/s/ls4/sw/ucx/1.9.0 $ mpirun apptainer run --bind $OMPI_DIR --bind $IB_DIR mpitest-bind.sif Hello, I am rank 0/4 Hello, I am rank 1/4 Hello, I am rank 2/4 Hello, I am rank 3/4
Опция --bind $OMPI_DIR подключает каталог с библиотеками OpenMPI.
Опция --bind $IB_DIR подключает каталог с дополнительными библиотеками, необходимыми для поддержки InfiniBand.
Примеры основаны на документации по использованию MPI для Apptainer, см. раздел Apptainer and MPI applications.
Запуск ПО с использованием GPU
Apptainer поддерживает работу с графическими ускорителями NVIDIA Tesla K80 и NVIDIA Tesla V100, используемыми на кластере HPC4.
Для запуска контейнера с поддержкой GPU достаточно добавить ключ --nv к опциям контейнера.
При сборке образа контейнера важно подготовить версии исполняемых файлов,
совместимые с GPU на кластере.
Для NVIDIA CUDA нужно указать требуемые версии CUDA Compute Capability.
Для K80 – версия 3.7, для V100 – версия 7.0.
Например, при компиляции с помощью nvcc необходимо добавить ключи:
$ nvcc x.cu -gencode arch=compute_37,code=sm_37 -gencode arch=compute_70,code=sm_70
На кластере доступны образы контейнеров NGC для библиотек PyTorch (/s/ls4/sw/apptainer/tensorflow_21.10-tf1-py3.sif) и Tensorflow (/s/ls4/sw/apptainer/pytorch_21.10-py3.sif)
Список очередей и политика их использования
При выборе очереди для запуска вашей задачи следует иметь в виду следующее:
- счётные очереди одного класса (например: hpc2-16g-*, hpc4-*, hpc5-gpu-*) используют общие для своего класса наборы одинаковых счётных узлов;
- счётные очереди различаются максимальным временем выполнения задачи и общим приоритетом задач;
- чем больше указанное вами при запуске максимальное время выполнения вашей задачи в выбранной очереди, тем меньше приоритет задачи в этой очереди.
Из этого следуют следующие рекомендации:
- задачу следует запускать в очереди, максимальное время выполнения задач в которой достаточно для выполнения вашей задачи;
- в параметрах запуска вашей задачи желательно указывать более точное значение максимального времени выполнения вашей задачи (т.е., менее, чем максимальное время выполнения задач в выбранной очереди). В этом случае ваша задача будет запущена быстрее задач в данной очереди, для которых указанное пользователями максимальное время выполнения их задач равно максимальному времени выполнения задач для данной очереди.
Кластер HPC2
В настоящее время пользователи могут запускать задачи в следующих очередях:
| Очередь | Назначение | Макс. время выполнения задачи | Количество узлов | Примечание |
|---|---|---|---|---|
| Отладка | 10 минут | 1 | Пользователь может запустить лишь 1 задачу | |
| Счёт | 3 суток | 1170 | ||
| Счёт | 7 суток | |||
| Счёт | 31 сутки | Доступ по согласованию |
Пояснения к таблице
- Во всех перечисленных очередях используются счётные узлы с двумя
четырехъядерными процессорами Intel Xeon E5450 с тактовой частотой
3.00 ГГц и 16 Гбайт оперативной памяти.
В данных процессорах не поддерживается технология Hyper-Threading, поэтому каждому узлу соответствует 8 ядер (и все они физические).
Операционная система: CentOS 5. - Во всех перечисленных счётных очередях (hpc2-16g-*) используется общее вычислительное поле из 1170 узлов.
- Если вам необходимо использовать очереди с доступом по согласованию, обратитесь
в нашу службу поддержки пользователей («helpcomputingkiaeru»), обосновав
необходимость.
Кластер HPC4
В настоящее время пользователи могут запускать задачи в следующих счётных очередях:
| Login-узел | Операционная система |
Очередь | Тип узла | Hyper-Threading | Ядер CPU на узел | Ядер GPU на узел | Макс. время выполнения задачи (суток) |
Количество узлов |
Примечание |
|---|---|---|---|---|---|---|---|---|---|
| CentOS 6 | n1 | Да | 48 | Нет | 3 | 253 | |||
| 7 | Доступ по согласованию | ||||||||
| g2 | Нет | 16 | 4 | 3 | 132 | ||||
| 7 | Доступ по согласованию | ||||||||
| Не используется | 3 | ||||||||
| 14 | Доступ по согласованию | ||||||||
| CentOS 7 | n1,n2 | Да | 48,56 | Нет | 3 | 104 | |||
| g1 | Да | 48 | 6 | 19 | |||||
| g2 | Нет | 16 | 4 | 10 | |||||
| Не используется | |||||||||
| g3 | Да | 40 | 4 | 1 | Доступ по согласованию |
Пояснения к таблице
-
Типы узлов
Тип узла Тип процессора Частота (ГГц) Процессоров на узел Ядер CPU на процессор Hyper-Threading Ядер CPU на узел Тип процессора GPU Ядер GPU на узел Оперативная память (ГБ) n1 Intel Xeon E5 2680 v3 2,50 2 12 Включён 48 - - 128 n2 Intel Xeon E5 2680 v4 2,40 2 14 Включён 56 - - 128 g1 Intel Xeon E5-2680 v3 2,50 2 12 Включён 48 NVIDIA Tesla K80 6 128 g2 Intel Xeon E5-2650 v2 2,60 2 8 Отключён 16 NVIDIA Tesla K80 4 128 g3 Intel Xeon E5-2630 v4 2,60 2 10 Включён 40 NVIDIA Tesla V100 4 64
- Hyper-Threading.
- В очередях c узлами типа g2 Hyper-Threading отключён, поэтому значение в графе "Ядер CPU на узел" соответствует суммарному количеству физических ядер CPU на обоих процессорах узла данного типа.
- Во всех прочих очередях Hyper-Threading включён, поэтому значение в графе "Ядер CPU на узел" соответствует удвоенному суммарному количеству физических ядер CPU на обоих процессорах узла данного типа.
- Очереди hpc5-3d, hpc5-2w и hpc5-el7-3d созданы для задач без использования GPU, но которым противопоказан Hyper-Threading (такие задачи неэффективно исполняются в прочих очередях). В этох очередях нельзя заказывать использование GPU.
- В очередях *-gpu-* на каждом узле доступно по M виртуальных ядер GPU
(значение M соответствует значению в графах "Ядер GPU на узел" в таблицах, приведённых выше).
При использовании в сценарии запуска задачи директивы#SBATCH --gres=gpu:N
N должно иметь значение от 1 до M (включительно). - Очереди hpc4-3d и hpc4-1w используют общее вычислительное поле.
- Очереди hpc5-gpu-3d, hpc5-gpu-1w, hpc5-3d и hpc5-2w используют общее вычислительное поле.
- Очереди hpc*-gpu-* и hpc5-v100-3d созданы исключительно для задач, использующих GPU. Заказ GPU в этих очередях обязателен.
- Очереди hpc*-el7-* и hpc5-v100-3d созданы для задач, работающих только в среде CentOS 7.
- Специальные очереди для отладки не предусмотрены.
- Если вам необходимо использовать очереди с доступом по согласованию, обратитесь
в нашу службу поддержки пользователей («helpcomputingkiaeru»), обосновав необходимость.
Ограничения ресурсов в очередях
Кластер HPC2
Во всех очередях кластера HPC2 действуют ограничения на размер виртуальной памяти для одного процесса. Эти пределы работают так, что если вы пытаетесь распределить памяти в сумме больше установленного предела, системные функции распределения памяти вернут нулевой указатель. Что с этим делать – решает сама задача, никто ее принудительно не убивает: задача
- либо завершается сама, если она не может пережить отсутствия нужного количества памяти
- либо продолжает считать, если она без этой памяти сможет обойтись
- либо выпадает в core, если автор программы не проверяет, выделили ли память или нет, а просто использует возвращенный указатель
Текущие ограничения на виртуальную память: 1,945,600 Кбайт виртуальной памяти на процесс.
Кластер HPC4
На HPC4 в настоящее время ограничений на системные ресурсы нет.Упоминание в публикациях
По условию использования ресурсов ЦКП руководитель группы и пользователи
должны в публикациях результатов, полученных с использованием ресурсов ЦКП,
ссылаться на ЦКП.
Подробная инструкция по данной теме помещена в документе
Декларация сотрудничества.
Иногда задаваемые вопросы
Как узнать, на каких узлах выполнялась программа
Список узлов содержится в переменной окружения SLURM_JOB_NODELIST. Значением этой переменной может быть, например «n[14,26-29]». Это означает, что задача выполнялась на узлах n14, n26, n27, n28 и n29.
Поэтому простейшим из способов сохранить эти данные в выводе вашей задачи будет добавление следующей строчки в сценарий запуска задачи:
echo "CPU list: $SLURM_JOB_NODELIST"Строчку можно добавить, например, после директив «module load».
Каким образом распределяются физические машины для каждой задачи
Чтобы различные пользовательские задачи не могли «отъесть» память друг у друга, каждой задаче выделяются свои физические машины. Скажем, запросив 20 ядер, вы получите 3 физических узла, на которых вам будет выделено 8+8+4 ядер (если каждый узел оснащен восемью процессорными ядрами). Никого больше на эти узлы, пока вы на них считаете, не пустят. Из этого следуют две вещи:
- Количество процессов лучше выбирать кратным количеству ядер на узлах.
- Иногда может быть так, что количество занятых всеми задачами ядер не равно полному количеству ядер в кластере, но тем не менее, все запускаемые задачи встают в очередь: для них просто может не быть свободных физических машин.
Как получить образ памяти (core dump) для программ, скомпилированных с помощью Intel Fortran.
Образ памяти иногда необходим для анализа ошибок в программе. По-умолчанию, для всех ошибок «severe» в Intel Fortran образ памяти на диск не сбрасывается. Если вам нужно получить этот образ, то нужно установить переменную окружения decfort_dump_flag в значение «y»:
export decfort_dump_flag=y
Скорее всего вы также захотите получать некоторую информацию об именах функций, номерах строк в исходных файлах и тому подобном. Для этого нужно скомпилировать отладочный образ вашей программы. Это можно сделать, указав при компиляции и компоновке флаг '-g', оповещающий инструментарий о том, что в исполняемый файл требуется включить отладочную информацию.
Кстати говоря, для Intel Fortran отладочный образ имеет еще одно свойство: при возникновении системных ошибок на экран выдаётся информация о последовательности вызова процедур, в которой будут присутствовать имена переменных, процедур и исходных файлов. Без использования отладочного образа, на месте перечисленных имен будет стоять грустное слово «Unknown».
У меня не работает самая простая MPI-программа на Fortran. Спасите!
Есть очень простая программа, которая выглядит так:
program mpi_probe
include 'mpif.h'
integer :: irank,isize,ierr
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD,irank,ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD,isize,ierr)
print *,'irank isize',irank,isize
call MPI_FINALIZE(ierr)
end
Программа запускается, но сразу валится в segmentation fault со следующей диагностикой:
forrtl: severe (174): SIGSEGV, segmentation fault occurred Image PC Routine Line Source libc.so.6 000000358F72E2B0 Unknown Unknown Unknown libmpi.so.1 0000002A95755D7B Unknown Unknown Unknown libmpi.so.1 0000002A9575EE08 Unknown Unknown Unknown a.out 0000000000402CFB Unknown Unknown Unknown a.out 0000000000402CA2 Unknown Unknown Unknown libc.so.6 000000358F71C3FB Unknown Unknown Unknown a.out 0000000000402BEA Unknown Unknown Unknown
Причин этому, конечно, может быть целая куча. Но одна из самых часто встречающихся ошибок следующая: у пользователя в том же каталоге, в котором компилируется программа, есть файл mpif.h. Причем файл этот, скорее всего, не от HP-MPI (или от HP-MPI, но другой версии). Поэтому не совпадают прототипы функций, типы переменных и, вообще, все плохо.
Мораль: таскать за собой какой-то mpif.h не нужно, даже если вы знаете, что он от нашей версии HP-MPI (чего вы знать не можете, поскольку версия иногда меняется). В системе уже есть mpif.h и он идет в комплекте с библиотекой HP-MPI. Более того, он автоматически берется из правильного места, если компилятор видит инструкцию «include 'mpif.h'». Поэтому об mpif.h заботиться не нужно. Более того, таскать этот файл за своей программой не только совершенно бессмысленно, но даже и вредно: система найдет этот заголовочный файл сама, поскольку данный файл является системным, принадлежит конкретной версии конкретной библиотеки MPI и ни в коем случае не является частью вашей программы.
Статические массивы размером более 2GB в Intel Fortran.
Если при компоновке вашей программы возникают сообщения следующего сорта
/tmp/ifort0ivMR0.o(.text+0xda): In function `output_t_': : relocation truncated to fit: R_X86_64_PC32 eos_par_mp_dens_ /tmp/ifort0ivMR0.o(.text+0x18a): In function `output_t_': : relocation truncated to fit: R_X86_64_PC32 eos_par_mp_dens_ /tmp/ifort0ivMR0.o(.text+0x18f): In function `output_t_': : relocation truncated to fit: R_X86_64_32 eos_par_mp_dens_ /tmp/ifort0ivMR0.o(.text+0x386): In function `output_t_': : relocation truncated to fit: R_X86_64_PC32 eos_par_mp_dens_ /tmp/ifort0ivMR0.o(.text+0x46d): In function `output_t_': : relocation truncated to fit: R_X86_64_PC32 eos_par_mp_dens_ /tmp/ifort0ivMR0.o(.text+0x472): In function `output_t_': : relocation truncated to fit: R_X86_64_32 eos_par_mp_dens_ /tmp/ifort0ivMR0.o(.text+0x59a): In function `output_t_': : relocation truncated to fit: R_X86_64_32 eos_par_mp_dens_ /tmp/ifort0ivMR0.o(.text+0x5cd): In function `output_t_': : relocation truncated to fit: R_X86_64_PC32 eos_par_mp_dens_ /tmp/ifortwpWEfe.o(.text+0xc): In function `pm_': : relocation truncated to fit: R_X86_64_PC32 tabhad_ /tmp/ifortwpWEfe.o(.text+0x5e): In function `pm_': : relocation truncated to fit: R_X86_64_32S tabhad_ /tmp/ifortwpWEfe.o(.text+0x6a): In function `pm_': : additional relocation overflows omitted from the outputто, скорее всего, у вас используются статические массивы размером более 2GB. Чтобы такие программы правильно собирались, к ключам компилятора на стадии сборки самой программы нужно добавить параметры «-mcmodel medium -shared-intel».
Еще одним вариантом является использование ключа «-mcmodel large», но этот ключ для большинства программ не нужен, и приводит только к увеличению их размера. Подробности можно узнать на техническом форуме Intel.
Как заставить работать FTP в Midnight Commander.
По-умолчанию, в Midnight Commander FTP работает в активном режиме. Настройки нашего кластера не позволяют работать в данном режиме, поэтому нужно попросить Midnight Commander использовать пассивный режим. Это очень просто: открываем файл «.mc/ini», ищем там раздел «[Midnight-Commander]» и добавляем туда строчку
ftpfs_use_passive_connections=1Если переменная «ftpfs_use_passive_connections» уже была определена, то заменяем её значение на единичку, как показано выше.
В результате, файл «.mc/ini» будет выглядеть так (многоточиями отмечены пропущенные строчки, не имеющие отношения к нашей проблеме):
… [Midnight-Commander] … ftpfs_use_passive_connections=1 …
Sbatch выдает сообщение «No partition specified or system default partition»
Такое сообщение возникает, когда вы не указали очередь, в которую хотите запустить свою задачу. Это нужно делать ключом командной строки «-p имя_очереди» или директивой SBATCH в файле сценария запуска:
#SBATCH -p имя_очереди
При компиляции программ на языке Fortran компилятором Intel выдается предупреждение о функции feupdateenv
При компиляции программ на Fortran компилятор фирмы Intel может выдавать следующее предупреждение:
/opt/intel/ifc/9/lib/libimf.so: warning: warning: feupdateenv is not implemented and will always failЭто всего лишь предупреждение и оно не влияет на нормальную работу программ. Вот объяснение от компании Intel, находящееся в заметках к компилятору Intel C/C++ 9.x:
In some earlier versions of Intel C++ Compiler, applications built for Intel EM64T linked by default to the dynamic (shared object) version of libimf, even though other libraries were linked statically. In the current version, libimf is linked statically unless -i-dynamic is used. This matches the behavior on IA-32 systems. You should use -i-dynamic to specify the dynamic Intel libraries if you are linking against shared objects built by Intel compilers. A side effect of this change is that users may see the following message from the linker: warning: feupdateenv is not implemented and will always fail This warning is due to a mismatch of library types and can be ignored. The warning will not appear if -i-dynamic is used.
Я поместил в .bash_profile «module load …», но при заходе на машину выдается сообщение об ошибке
Файл ~/.bash_profile в редакторе vi выглядит следующим образом:
module load openmpi intel-compilers ~ ~ ~ ".bash_profile" [dos] 2L, 54CПри заходе на кластер выдается сообщение об ошибках:
: No such file or directory -bash: module: command not foundПричина проста: файл .bash_profile был создан в DOS/Windows и затем был перенесен в Unix. Это видно по наличию символов «[dos]» в строке статуса редактора vi. Нужно отметить, что реальное содержимое файла ~/.bash_profile особенного значения не имеет – важно то, что сам файл был создан в DOS/Windows, поскольку именно это приводит к ошибкам.
Решение проблемы простое: нужно перекодировать файл из DOS/Windows в Unix-кодировку. Для этого достаточно набрать команду «dos2unix имя_файла», которая перекодирует указаный файл из кодировки DOS (CP866) в кодировку Unix (KOI8-R). В нашем случае нужно дать команду «dos2unix ~/.bash_profile».
Программа на языке Fortran завершается, говоря «MPI_ERR_TYPE: invalid datatype»
Скорее всего, в вашей программе не объявлены параметры MPI_REAL, MPI_INTEGER и другие, отвечающие за тип передаваемых данных при приеме/пересылке. Побороть это возможно включением инструкции "include 'mpif.h'" в вашу программу. Естественно, причина может быть еще более простой: вы указали неправильный (или незарегистрированный) тип данных MPI.
Обратите, пожалуйста, внимание, что в программе следующего вида
program main
include 'mpif.h'
print *, "m = ", mpi_real
call test
end
subroutine test
print *, "m-test = ", mpi_real
end
program main
include 'mpif.h'
print *, "m = ", mpi_real
call test
end
subroutine test
include 'mpif.h'
print *, "m-test = ", mpi_real
end
Работа с кириллическим текстом
На login-узлах кластеров по умолчанию настроена кодировка KOI8-R. Поэтому, если ваша клиентская программа понимает кириллические кодировки, достаточно указать ей данную кодировку и вы получите возможность работать с родным языком ;))
Другой возможной проблемой является то, что файлы, которые вы копируете на login-узлы кластера, могут быть в кириллических кодировках, отличных от KOI8-R. Но это поправимо: на login-узлах установлена программа «iconv», которая умеет преобразовывать файлы из любых кодировок в любые. Например, команда
iconv -f cp866 -t koi8-r infile > outfile
Странные падения программ на Fortran
Иногда бывает так, что программы, полностью или частично написанные на Fortran, валятся в segmentation fault без видимой причины. Если посмотреть на проблему в отладчике, то будет видно очень странное: точное место, где все заканчивается – это машинная инструкция «call».
Очень часто эта проблема возникает потому, что у программы заканчивается стек: некоторые авторы программ на Fortran любят делать большие локальные массивы в подпроцедурах и не использовать для этого динамическую память. Однако, разработчики Intel Fortran уже об этом подумали и сделали ключ компилятора «-heap-arrays». Он перемещает все локальные массивы в динамическую память, значительно облегчая нагрузку на стек.
Попробуйте, может быть, этот ключ спасёт вас от падений программы.
Хочется использовать больше памяти, чем есть на ядро
Бывают параллельные задачи, которым не хватает памяти, скажем, из расчета 1 GB/ядро и вычислительные процессы задачи организованы так, что каждый из них потребляет примерно одинаковое количество памяти. Понятно, что если таких процессов на рабочем узле живет столько, сколько есть ядер, то дело плохо.
Один из вариантов решения проблемы – сказать Slurm, что мы хотим выделять не одно ядро под процесс, а несколько. Для этого есть директива
#SBATCH --cpus-per-task Nгде N – это как раз число ядер, выделяемых для каждого процесса.
Эффективно это приведет к тому, что каждому из процессов будет доступно не менее чем N*k GB оперативной памяти на машинах с k GB/ядро.
Задача сразу завершается не оставляя сообщений об ошибках
Данная проблема чаще всего возникает, когда в файле сценария указан неверный путь к рабочему каталогу:
#SBATCH -D /s/ls2/users/eygene/my-precious-taskПроверьте, что каталог находится в файловой системе Lustre (путь начинается с /s/), что путь указан верно и у вас есть доступ к указанному каталогу.
В моём каталоге появились странные файлы core.*
Файлы core.* образуются тогда, когда ваша программа обращается к недопустимой области памяти или делает ещё какую-то некорректную операцию; операционная система это ловит и завершает программу аварийно, тем не менее, давая возможность программисту или пользователю попробовать разобраться, что именно она пыталась сделать.
Задача не начинает расчет, а висит со статусом PD, AssocGrpCpuLimit
Данный статус говорит о том, что задача упирается в ограничение количества одновременно используемых ядер для вашей группы. Обычно ограничение составляет 2048 ядер на группу. Важно, что при одновременном использовании в сценарии команд
#SBATCH -n Nи
#SBATCH --cpus-per-task Mсценарий занимает N*M ядер. Сумма занятых ядер по всем запущенным задачам участников группы не должна превышать установленное ограничение.